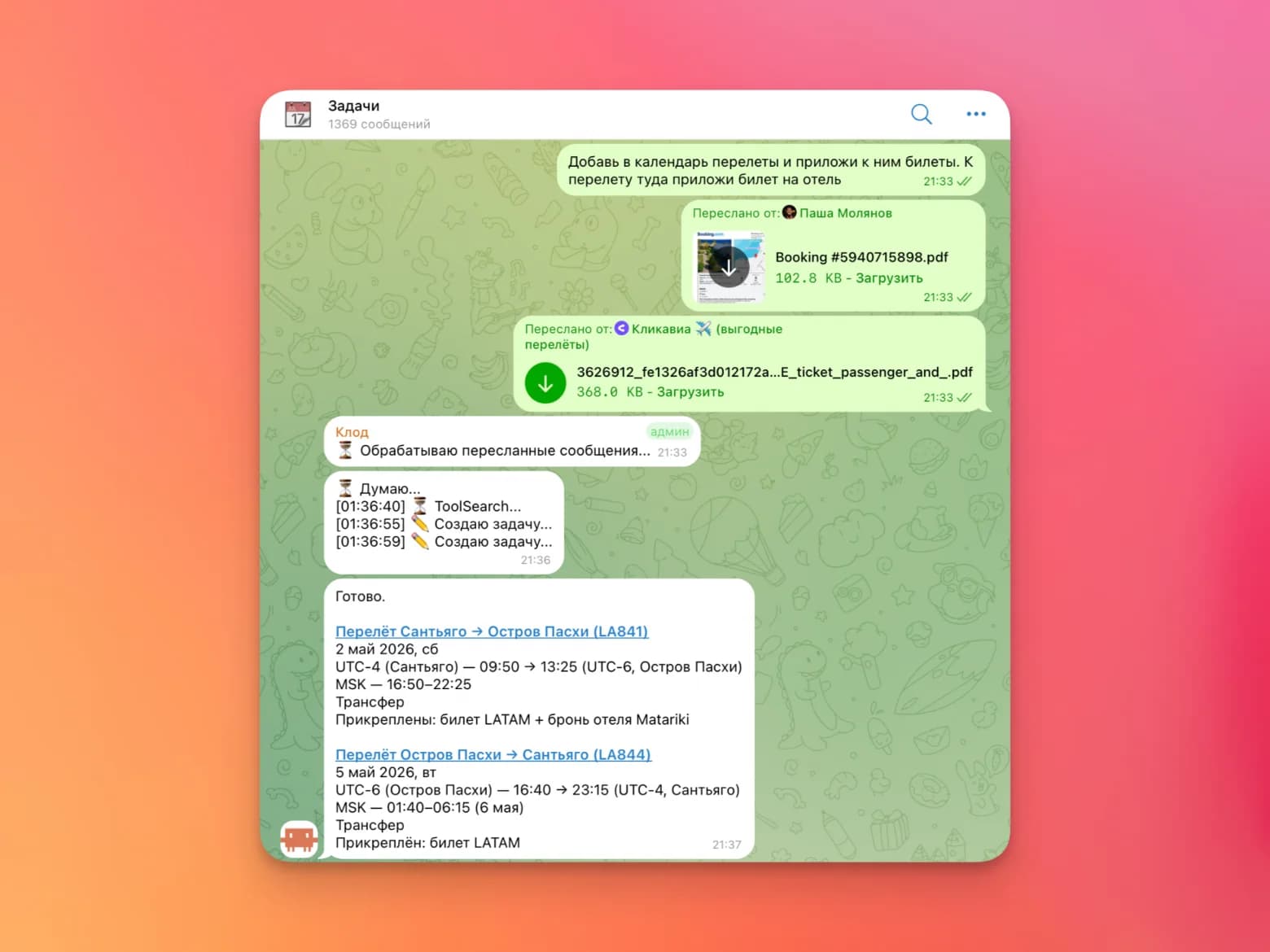
CLAUDE.md и AGENTS.md: как документировать проект для вайбкодинга, чтобы агент реже ошибался
Допустим, у вас интернет-магазин косметики. Вы просите агента (Claude Code или Codex) добавить на карточку товара кнопку «Поделиться». Дело на пять минут: таких кнопок на сайте уже штук пять, нужна шестая, ровно такая же. Вот только для агента это первый день на работе. Он не знает, где лежат эти кнопки, как они устроены, какими командами всё запускается и что в проекте трогать нельзя.
Если не дать ему нормальный вход в проект, он лезет читать всё подряд, жжёт лимиты, а потом вместо «ещё одной такой же» лепит свою кнопку с нуля — не похожую на остальные. Заодно правит соседний блок, который его не просили трогать, и в конце бодро говорит «готово», хотя половина вёрстки съехала. Открываете новый чат — и всё по новой: агент как будто с амнезией, снова не помнит про проект ничего.
Ровно эту проблему решают CLAUDE.md и AGENTS.md. Это обычные текстовые файлы с лёгкой разметкой (формат Markdown) и проектными инструкциями для AI-агентов: короткий курс молодого бойца, где что в проекте лежит и как с ним работать. Claude Code читает CLAUDE.md и держит его как память проекта. Codex и другие OpenAI-агенты читают AGENTS.md. Оба лежат в корне проекта. Если работаете сразу с двумя инструментами, держите оба файла. Проще всего сделать второй копией первого — содержимое у них почти одинаковое. У Cursor логика похожая, только своя система: у него есть Rules (его собственный формат правил для проекта) и поддержка AGENTS.md — записываете то, что редактор должен постоянно держать в голове при работе с проектом.
Гарантий эти файлы не дают. Anthropic прямо пишет: Claude старается держаться CLAUDE.md, но следует ему не всегда — особенно если инструкции расплывчатые или спорят друг с другом. Но даже так файл экономит повторные объяснения и помогает агенту быстрее войти в проект.
Что написать в первом CLAUDE.md или AGENTS.md
У вас есть проект и пустой файл. Сразу вылизывать документ на все случаи жизни не нужно — на первом заходе хватит минимума, после которого агент перестаёт путаться в проекте. Вот что стоит в него положить:
- Что делает проект. Одно-два предложения, чтобы агент понимал, к чему прикручивает свой код.
- Какой стек — на каких технологиях и библиотеках сделан проект. Чтобы агент не притащил ещё одну библиотеку туда, где всё уже решается имеющимися.
- Где что лежит. Карта основных папок. Чтобы он не искал ту самую кнопку по всему проекту.
- Как запустить локально. Точные команды, а не «запустите проект».
- Команды проверок: тесты, линт (автоматическая проверка стиля и простых ошибок в коде), сборка (превращение исходников в готовое к запуску приложение), деплой (выкладка готового проекта на боевой сайт). Чтобы агент не говорил «готово» без доказательств.
- Где искать существующие функции перед тем, как писать новые. Чтобы он не плодил третью реализацию того, что уже написано дважды.
- Что трогать нельзя без согласования. Чтобы одна кнопка «заодно» не превратилась в переписывание половины страницы.
- Как сдавать результат. Что агент должен показать в конце: какие команды прогнал, что прошло.
Примерно тот же список советует класть в AGENTS.md сам OpenAI: структуру репозитория (папки с кодом проекта), команды запуска и сборки, тесты, договорённости и критерий готовности.
Главное в формулировках — конкретность. Размытое пожелание агент понимает как хочет, точную инструкцию выполняет буквально — это же советует и Anthropic. Скажешь «делай кнопки как надо» — агент сам решит, что такое «как надо», и сделает по-своему. Скажешь «новую кнопку собирай из готового компонента Button, не рисуй с нуля» — выбора нет, сделает как написано.
Собрать всё это вместе для нашего магазина косметики — и первый CLAUDE.md выглядит так:
# CLAUDE.md — интернет-магазин косметики
## Что это за проект
Витрина косметики: каталог товаров, карточки, корзина, оформление заказа.
Заказы уходят во внешнюю CRM. Цель — продавать, поэтому скорость и SEO важны.
## Стек
- Next.js (App Router) + TypeScript + Tailwind — витрина и страницы.
- Node.js — бэкенд, простой API-слой.
- PostgreSQL — база с каталогом и товарами, доступ к базе через Prisma.
- Zod — проверка входящих данных на границе API.
## Где что лежит (карта папок)
- `src/app` — страницы и роуты (то, что видит покупатель).
- `src/components` — переиспользуемые кусочки интерфейса (кнопки, карточки).
- `src/lib` — работа с базой и внешними API (Prisma, CRM).
- `src/content` — тексты страниц и SEO-описания.
## Как запустить локально
- `npm run dev` — поднять сайт на своём компьютере для проверки.
## Команды проверок
- `npm test` — прогнать тесты (убедиться, что ничего не сломалось).
- `npm run build` — собрать проект как для боевого сервера.
- Деплой: `git push` в ветку `main` — дальше Vercel сам соберёт и выкатит.
## Прежде чем писать новое
- Сначала поищи готовое: UI-компоненты в `src/components`, работу с базой и CRM в `src/lib`.
- Не плоди дубли — если похожая функция уже есть, переиспользуй её.
## Трогать нельзя без моего согласия
- Страницу оплаты, корзину и интеграцию с CRM — сначала спроси, потом меняй.
## Как сдавать результат
- Коротко: что менял и зачем.
- Покажи, что `npm test` и `npm run build` проходят.
- Если менял внешний вид — приложи скриншот страницы.
Это не значит, что первый файл обязан быть таким подробным. На совсем маленьком проекте хватит и трёх пунктов — что за проект, как запускать и проверять, что не трогать. Остальное допишете, когда проект вырастет.
Одно важно не смешивать: CLAUDE.md/AGENTS.md — это не замена README. README — устоявшийся вход для людей: разработчика, ревьюера, случайного посетителя на GitHub. Он рассказывает, что это за проект, как его поставить, запустить, настроить и проверить. Сайт AGENTS.md даже специально разводит эти два слоя: README для людей, AGENTS.md — для агентских инструкций по сборке, тестам и договорённостям, которые в README только мешали бы. Так что эти файлы не вместо README, а рядом: README объясняет проект человеку, CLAUDE.md/AGENTS.md говорит агенту, что помнить в каждой сессии, какие команды запускать и каких границ не переходить.
Разложите правила по уровням: общие, проектные и по задаче
Скорее всего, проект у вас не один. И часть правил повторяется во всех: «отвечай по-русски», «пиши кратко», «не коммить без спроса». Копировать их в каждый проектный CLAUDE.md — лишняя работа и лишний риск, что где-то забудете обновить. Такие общие правила выносят в один глобальный файл, который агент читает во всех проектах сразу. Всего уровней получается три, и у каждого своё место.
Глобальные инструкции — то, что верно для всех проектов и всех чатов. «Отвечай по-русски», «не коммить без просьбы», «не свети ключи и доступы», «предупреждай о рисках», «пиши кратко». Это ваши операторские правила, они живут в глобальном файле: у Claude Code это ~/.claude/CLAUDE.md, у Codex — файл в его домашней папке ~/.codex. OpenAI прямо так и рекомендует: личные настройки поведения — в глобальный файл, правила команды и кодовой базы — в файлы репозитория.
Рядом с магазином у вас наверняка есть и другие проекты — лендинг, бот, ещё сайт. Правила «отвечай по-русски» и «не коммить без спроса» одинаковы для всех, поэтому и живут в глобальном файле. У предпринимателя, который не пишет код сам, он может выглядеть так:
# ~/.claude/CLAUDE.md — общие правила для всех проектов
## Кто я
- Я предприниматель, не программист. Код сам не читаю.
- Объясняй простыми словами, без жаргона. Термин ввёл — сразу расшифруй одной фразой.
- Отвечай по-русски.
## Как со мной работать
- Сначала короткий план на пару строк — что и зачем собираешься делать. Потом код.
- Дождись моего «да» на план, если правка большая или рискованная.
- Предупреждай о рисках ДО того, как что-то менять, а не после.
## Что без моего явного согласия делать нельзя
- Не коммить изменения.
- Не пушить и не деплоить (`git push`, выкатка на боевой сайт).
- Не удалять файлы и не сносить данные.
## Секреты и доступы
- Никогда не пиши пароли, ключи и токены в чат или в файлы.
- Нужен доступ — скажи, куда его положить самому (`.env`, секреты хостинга), сам ключ мне не показывай.
## Инструменты и зависимости
- Не тащи новую библиотеку, если задача решается тем, что уже есть в проекте.
- Меньше «магии»: простое понятное решение лучше хитрого.
Проектный файл — всё, что нужно любому агенту, который работает над этим проектом сейчас или будет потом: стек, команды, структура, ограничения, проверки, где искать знания. Это тот самый CLAUDE.md/AGENTS.md в корне.
Контекст задачи — наоборот, всё сиюминутное: что делаем прямо сейчас, какие файлы уже обсудили, какое ограничение живёт только в этой работе. Этому в CLAUDE.md не место — оно устареет уже завтра. Заведите под это отдельный файл задачи и держите такой контекст там.
Простой тест, куда положить правило. «Отвечай по-русски» — глобально, это про вас, не про конкретный проект. «Запускай сборку через npm run build» — проектный файл, у другого проекта команда будет своя. «В этой задаче не трогаем оплату» — файл задачи, это верно только сегодня. И поверх всех трёх уровней, отдельно и жирным: секреты, доступы и приватные маршруты не кладём никуда — ни в глобальный файл, ни в проектный, ни в задачу.
Когда один файл начинает забивать агенту контекст
Магазин растёт, вы дописываете в его CLAUDE.md всё подряд — вёрстку, дизайн карточек, SEO, тексты для товаров, деплой, работу с CRM, правила ревью и ещё пяток договорённостей. Всё в одном месте, вроде удобно.
А потом вы просите агента поднять SEO карточек — и он по дороге читает правила вёрстки и инструкцию по деплою. Просите агента-дизайнера поправить экран корзины — он тащит в контекст логи, проверки и бизнес-правила. Просите кодера поправить один компонент — ему прилетают инструкции по SEO и текстам. Каждый агент получает весь ворох, хотя нужен ему один кусок.

За раздутый контекст приходится платить точностью. Чем больше токенов (кусочков текста, которыми модель меряет объём, — примерно слово или часть слова) в контексте, тем хуже модель их держит. Anthropic называет это «context rot»: чем больше токенов, тем ниже точность, с какой модель вспоминает нужное. Внимание модели у них — бюджет, который тратится с каждым новым токеном, и совет отсюда прямой: класть в контекст только нужное под задачу. А ещё модель лучше помнит начало и конец длинного текста и проседает в середине. Это так и называют — «потерялся в середине». С ростом длины входа качество заметно падает даже у моделей с большим окном контекста.
Ломается это плавно, без обрыва. Длинный файл не отключит агента разом — просто каждый лишний абзац чуть-чуть снижает шанс, что нужное правило вспомнится и сработает. Сила эффекта зависит от модели: новые держат длинный контекст лучше, но совсем он не исчезает.
Проблема поменялась. В начале агент ничего не знал о проекте — мы дали ему файл. Теперь он знает слишком много лишнего под конкретную задачу: агенту, который правит корзину, незачем таскать в контексте правила про дизайн карточек и тексты для товаров. Про то, что агенту нужен минимум полезного контекста, а не весь проект целиком, я подробнее писал в двух правилах работы с ИИ-агентами: меньше контекста и больше самопроверок. Раз проблема в лишнем знании, то и решение про это: дать агенту способ подтянуть под задачу только нужный кусок.
Сделайте CLAUDE.md или AGENTS.md точкой входа, а знания разнесите по отдельным файлам
Корневой CLAUDE.md или AGENTS.md остаётся коротким маршрутизатором, а подробные знания уезжают в отдельные файлы по темам — код, дизайн, SEO, деплой (программисты называют это доменами). В корневом файле не надо рассказывать всё про дизайн, SEO, логи, деплой и архитектуру. Его работа — сказать агенту, куда смотреть: задача про код — сюда, про дизайн — туда, про SEO — вот в этот документ, про деплой — в тот.

Тот же принцип OpenAI формулирует как «держите главный AGENTS.md коротким, а планирование, ревью и архитектуру выносите в отдельные документы, если файл разрастается». Anthropic называет это прогрессивным раскрытием: MEMORY.md работает как индекс, а подробные тематические файлы читаются по необходимости.
В росте это выглядит так: сначала один CLAUDE.md/AGENTS.md с базовыми правилами. Потом рядом появляется папка docs/ или project-knowledge/ с отдельными документами — по архитектуре, стеку, дизайну, SEO, контенту, деплою, логам, тестированию, бизнес-правилам. Потом добавляются файлы задач, чеклисты, hooks и CI — автоматические проверки, до которых мы дойдём ниже.
Сайт molyanov.ru, который вы сейчас читаете, я разрабатываю и поддерживаю с помощью агентов. Покажу, как устроена реальная документация, которую я даю им перед работой. Корневые CLAUDE.md и AGENTS.md короткие — около 35 строк каждый — и различаются одной строкой пути. Ключевая строка ведёт в базу знаний проекта — папку project-knowledge с гайдами по архитектуре, паттернам, git-процессу, UX, базе данных и деплою. Внутри — оглавление SKILL.md и пять доменных файлов:
CLAUDE.md / AGENTS.md ← короткий вход, ~35 строк
└── .claude/skills/project-knowledge/
├── SKILL.md ← оглавление базы знаний
├── project.md ← что за проект и для кого
├── architecture.md ← стек, структура, модель данных
├── patterns.md ← стандарты кода, git-процесс, SEO, тесты
├── deployment.md ← платформа, окружения, откат, мониторинг
└── ux-guidelines.md ← дизайн-система, доступность
Само оглавление SKILL.md и есть тот самый маршрутизатор. Вот реальный кусок из него — по нему агент решает, какой документ открыть под задачу (файл у меня на английском, привожу как есть):
## How to use
- Starting feature development — read project.md, architecture.md, patterns.md
- Working on data/content changes — read architecture.md (Data Model section)
- Working on UI/UX — read ux-guidelines.md
- Setting up deployment or monitoring — read deployment.md
- Creating branches or PRs — read patterns.md (Git Workflow section)
По-русски правило читается так: пришла задача про интерфейс — агент открывает только ux-guidelines.md, задача про деплой — только deployment.md, а SEO живёт секцией внутри patterns.md, отдельного файла под него нет. Ни деплой, ни дизайн-гайд, ни правила текстов в контекст при этом не тащатся. Корневой файл сам ничего не пересказывает — он только направляет.
CLAUDE.md и AGENTS.md — это верхний слой базы знаний проекта. Как вести саму базу знаний в вайбкодинге — что выносить в отдельные документы, как держать контекст коротким — я разбирал в 12 советах, как кодить с ИИ, и как вести базу знаний проекта в вайбкодинге.
Вернёмся к нашему магазину — он к этому моменту вырос так же. Минимальный CLAUDE.md со старта превратился в короткий вход плюс доменные файлы, и внутри такого файла лежит уже конкретика под задачу. Вот его architecture.md. Переносить к себе стоит не конкретные технологии из примера, а сами три заголовка: «Стек», «Где что лежит», «Важные пакеты». Это скелет, который вы заполните своими технологиями и папками:
# Архитектура — интернет-магазин косметики
## Стек
- Next.js (App Router) — фронтенд и роутинг страниц.
- TypeScript — типизированный код (меньше случайных ошибок).
- Tailwind — стили через готовые классы.
- Node.js — бэкенд, простой API-слой.
- PostgreSQL — база данных: каталог и товары.
- Prisma — слой доступа к базе (запросы вместо ручного SQL).
- Zod — проверка входящих данных на границе API.
- Внешняя CRM — принимает заказы по API.
## Где что лежит
- `src/app` — страницы и роуты, которые видит покупатель.
- `src/components` — переиспользуемые UI-компоненты (кнопки, карточки товара).
- `src/lib` — работа с базой (Prisma) и внешними API (CRM).
- `src/content` — тексты страниц и SEO-мета (заголовки, описания).
## Важные пакеты
- `@prisma/client` — обращение к PostgreSQL из кода, схема базы в `prisma/schema.prisma`.
- `zod` — описываем форму входящих данных и отсекаем «мусор» до попадания в базу.
- `next` — сам фреймворк витрины (роутинг, рендер страниц, сборка).
- `tailwindcss` — оформление интерфейса, настройка в `tailwind.config.ts`.
Если половина слов тут незнакома — не страшно, их писал агент под конкретный стек. Если вы не программируете сами, вам важно не содержимое, а то, что файл отвечает на три вопроса: на чём проект сделан, где что лежит и какие пакеты трогать осторожно. Вот эту форму и стоит унести к себе.
Целиком такую раскладку в живом виде я выложил в открытый репозиторий pavel-molyanov/molyanov-ai-dev: там та же папка project-knowledge в шаблоне нового проекта, доменные файлы в references/ и рядом инструменты, которыми база знаний наполняется. Документацию molyanov.ru целиком не публикую — в реальных файлах деплоя лежат доступы и приватные детали, поэтому публичный пример обезличенный. И сама база знаний — только часть более широкого подхода к работе с агентами, целиком про него я рассказал в моём фреймворке агентной разработки.
Если внутри проекта есть подпроект, положите правила рядом с ним
Бывает, что под одной крышей живёт сразу несколько проектов: сайт, админка, бот, документация, инфраструктура. Или монорепозиторий — один репозиторий, внутри которого живёт несколько приложений или пакетов. Корневой файл описывает общие правила, но внутри apps/site/, apps/admin/ или infra/ могут быть свои команды, свой стек, свои ограничения и проверки.
В таком случае рядом с подпроектом кладут свой файл правил — CLAUDE.md, AGENTS.md или, если вы в Cursor, его файл правил. Инструменты это поддерживают. Claude Code читает CLAUDE.md, начиная от папки, где идёт работа, и поднимаясь к корню, а файл во вложенной папке подхватывает, только когда агент туда заходит. Codex собирает инструкции от корня до текущей папки, и тот файл, что ближе, перекрывает более общие правила. Cursor делает так же — вложенные правила у него важнее родительских. Механики немного разные, но идея одна: файл ближе к коду — правила ближе к делу.
Вложенный файл нужен, если внутри этой части проекта реально другие команды, стек, ограничения или проверки. Не нужен, если правило одинаковое для всего проекта — тогда оно живёт в корневом файле или в глубокой документации. Худший вариант — размножить одну и ту же копипасту правил по всем папкам: правило поменялось, а вы уже не помните, в каком из пяти файлов его обновлять, и они начинают тихо расходиться.
Переписывайте пожелания в правила, которые агент может выполнить
Большая часть бесполезных правил в таких файлах — моральные советы, которые агент легко игнорирует, потому что не понимает, что конкретно делать. Лечится это переводом пожелания в действие, запрет, проверку или ссылку на конкретный документ.
В файле магазина уже есть команды и запреты. Теперь добавим правила, которые агент может выполнить. Формулировки ниже — из реальных ошибок, которые у меня повторялись. Слева — как хочется написать, справа — как агент реально сможет выполнить.
- «Пиши чистый код» → «перед созданием нового сервиса найди существующие поиском по проекту через
rg(быстрый поиск по файлам) и переиспользуй — или объясни, почему делаешь новый». - «Не раздувай решение» → «меняй минимальный набор файлов, а отдельный рефакторинг (переделку кода без изменения того, что он делает) согласуй до правок».
- «Не ломай проект» → «перед сдачей запусти команды X, Y, Z и напиши, что прошло».
- «Смотри логи» → «бери безопасный маршрут из документа про логи, доступы по серверу не ищи».
Левая колонка — оценка, которую агент не может проверить на себе, правая — конкретное действие с понятным результатом. «Пиши чистый код» каждый понимает по-своему, в том числе агент. «Найди существующие через rg и переиспользуй» проверяемо: либо искал, либо нет. Последний пример — про логи — из моей практики: без документации агент лезет искать логи по серверу наугад, а с одной строчкой про безопасный маршрут сразу понимает, куда идти. Приватные пути и доступы в такой инструкции, разумеется, не пишут — только ссылку на документ, где маршрут описан.
Отсюда критерий хорошего правила. Оно задаёт одно из пяти: действие, запрет, проверку, критерий готовности или ссылку на конкретный документ. Всё остальное — благие пожелания, которые звучат разумно и не работают.
Самое важное вынесите из текста в автоматические проверки
Есть правила, которые слишком важны, чтобы держать их одним предложением в тексте. Возьмём «не пиши секреты» из глобального файла магазина. Одна строчка в тексте — это только надежда, что агент вспомнит её в нужный момент. Особенно шаткая, если файл длинный. Такое правило надёжнее застраховать проверкой, которая не забывает.
OpenAI советует ровно это: не полагаться на текст AGENTS.md, а подпереть его автоматикой, которая правила не просит соблюдать, а принуждает. Это программы, которые сами проверяют каждое изменение агента — прогоняют тесты, сверяют код и формат, ищут утёкшие пароли и ключи — и не пускают дальше то, что не прошло. И даже когда агент отрапортовал «готово», стоит заглянуть в diff — список строк, которые он изменил. Текст агент может проигнорировать, а провалившуюся проверку — нет.
За этими проверками — несколько инструментов, каждый закрывает свой участок:
- Хук — маленькая программа, которая сама срабатывает в нужный момент. Например,
PreToolUseв Claude Code перехватывает опасную команду ещё до того, как агент её выполнит. pre-commit— запускает быстрые проверки при каждом сохранении изменений, а заодноgitleaksловит случайно попавшие в код пароли и ключи.- CI (например, GitHub Actions) — независимо проверяет изменения перед тем, как их принять: собирает проект, гоняет тесты, показывает результат.
- Проверка типов — следит, чтобы код не путал число с текстом.
Помнить эти названия вам не нужно — агент настроит их сам, если попросить. Важно другое: критичное правило можно отдать под автомат, и тогда оно не зависит от того, вспомнит агент строчку в файле или нет.

Одну ошибку тут делают часто: дублируют в инструкции то, что и так ловит линтер или форматтер. В одном исследовании AGENTS.md-файлов такое повторение оказалось самой частой проблемой — его нашли в 62% файлов выборки. Если проверку делает автоматика, правило в тексте не нужно: оно только раздувает файл и роняет ту самую точность, ради которой мы контекст и подрезаем.
Автоматика ловит только механические ошибки: что проект собирается, что секрет не утёк, что тесты зелёные. Архитектурные решения и продуктовые риски она не ловит — их всё равно ревьюит человек. Тесты и хуки снимают с ревью рутину, чтобы человек смотрел на важное.
| Желание в инструкции | Надёжная опора | Что ловит |
|---|---|---|
| Не коммить секреты | gitleaks / скан секретов | ключи и пароли в изменениях |
| Не ломай сборку | build и проверка типов в CI | проект собирается, типы целы |
| Пиши тесты | критерий готовности + прогон тестов | что рабочие сценарии остались рабочими |
| Не ломай незаметно то, чем пользуются другие части системы | тесты / контракт / ревью | поломку договорённости между частями системы |
| Докажи, что работа готова | финальный ответ с командами, логами или скрином | даёт человеку быстрый след проверки |
Обновляйте инструкции после ошибок агента, а не по расписанию
CLAUDE.md и база знаний становятся полезными только когда в них попадают правила из реальной работы. Сгенерированный на старте файл — это гипотеза о проекте. Полезным он делается, когда вы дописываете в него то, на чём агент реально споткнулся.
Дальше всё идёт по кругу: агент ошибся → называем тип сбоя → выбираем правильный слой для исправления → проверяем, что ошибка не повторяется. OpenAI описывает ровно этот цикл обратной связи: обновляйте AGENTS.md, когда агент повторяет ошибку, читает лишние документы или снова ловит один и тот же комментарий на ревью. Anthropic со стороны CLAUDE.md добавляет диагностику: проверьте, что файл вообще загрузился, сделайте инструкцию конкретнее, поищите правила, которые конфликтуют между собой. А если действие должно срабатывать в строго определённый момент — тут нужен хук, текстом не обойтись.

Ключевое тут — выбрать правильный слой. По привычке всё летит в корневой файл, и это зря. Один и тот же сбой лечится в разных местах:
| Сбой агента | Что менять |
|---|---|
| Выдумал новую функцию вместо существующей | правило поиска в проектном файле + ссылка на архитектуру |
| Раздул решение | правило минимального набора изменений + согласование рефакторинга |
| Полез искать логи опасным путём | глубокий документ с безопасным маршрутом |
| Не запустил тесты | критерий готовности + CI |
| Ошибается только в одном модуле | локальная инструкция или модульный тест |
| Один и тот же спор на ревью | обновить чеклист задачи или правило приёмки |
Строка про логи в таблице выше — ровно такой выбор слоя: повторяющаяся боль ушла в отдельный документ и перестала переписываться в промпт заново каждый раз.
Чтобы это не держалось на силе воли, полезно встроить обновление в процесс. У меня есть команда /done: когда фича закончена, агент читает спеки и решения по ней, обновляет затронутые файлы базы знаний, архивирует задачу и коммитит изменения документации. То есть знание фиксируется не «когда-нибудь потом», а прямо в момент завершения работы. Про то, как вообще приучить агентов накапливать опыт в инструкциях, я отдельно писал — лучшая привычка в работе с ИИ-агентами: заставлять их накапливать опыт.
Проверьте свой файл и оставьте агенту только полезный маршрут
Пройдитесь по своему CLAUDE.md, AGENTS.md или правилам Cursor и честно ответьте:
- Понятно ли, какой агент читает этот файл: Claude Code — CLAUDE.md, Codex — AGENTS.md, Cursor — Rules или AGENTS.md?
- Отделены ли ваши личные привычки от правил проекта?
- Есть ли базовый курс молодого бойца: команды запуска, тестов, линта и критерий готовности?
- Не разросся ли корневой файл в свалку обо всём?
- Есть ли маршруты к доменным документам, а не пересказ их содержимого?
- Есть ли карта, где искать существующие функции и глубокую документацию?
- Объясняют ли ссылки на документы, когда их читать, — или висят без контекста?
- Нет ли в файле секретов, приватных доступов и опасных команд?
- Конкретные ли правила и проверяемые? Критичное подпёрто хуком, тестом или CI?
- Не противоречат ли друг другу CLAUDE.md, AGENTS.md, правила Cursor, hooks и CI?
- Понятно ли, что обновлять после повторяющейся ошибки?
И маршрут на сегодня, если файла ещё нет или он давно превратился в свалку. Создайте файл под свой инструмент. Напишите минимальный курс молодого бойца: стек, команды, карта папок, критерий готовности. Отделите глобальные привычки от проектных правил. Если файл уже пухнет — вынесите доменные знания в отдельные документы, а в CLAUDE.md/AGENTS.md оставьте маршруты к ним. Закрепите одну повторяющуюся ошибку в правильном месте: в инструкции, документе, тесте, хуке или процессе. А через неделю вернитесь и удалите из файла всё, что не помогает агенту принимать решения.
Такие файлы помогают ровно до тех пор, пока они короткие, конкретные, проверяемые и вы поддерживаете их после реальных ошибок. Но если файл сгенерировали на старте и забыли — он быстро превращается в такой же шум, от которого мы уходили.
Если вам зашла тема вайбкодинга и работы с агентами — подписывайтесь на мой телеграм-канал по кнопке ниже. Там я делюсь опытом из первых рук: как запускаю и продвигаю соло-проекты с помощью ИИ, как автоматизирую рутину в своём бизнесе и что из этого реально работает, а что нет.

Паша Молянов
Автор блога
Основатель агентства «Сделаем» и Нейроцеха. В маркетинге с 2015 года, с 2018 года управляю бизнесом. С 2025 года запускаю небольшие соло-проекты с помощью ИИ. Рассказываю про свой опыт в Телеграм-канале.

Молянов
В Телеграм канале каждый день рассказываю про бизнес, нейросети и диджитал. А еще показываю, как сочетать постоянные путешествия с предпринимательством и работой.